In today’s lesson, we will be building towards real-world examples for better context and implementation.
Over the Moon on Basic Neural Networks
Let’s open up the file(s) in the 01-Ins_OverTheMoon folder to get started.
Students Do: Back to the Moon
Let’s open up the file(s) in the 02-Stu_BackToTheMoon folder to get started.
Getting Hands On with Model Optimization
Let’s open up the file(s) in the 03-Ins_SynapticBoost folder to get started.
In ML, irregardless of whether it is deep learning or other forms of ML, it is important to:
- Weigh the features (input variables, independent variables)
- Reduce noise (removing columns or rows that might disrupt the real-world effectiveness of the model)
In the above activity, we see how some of the reaction times have extraordinary outliers. Based on business context, it may be necessary to remove these outliers as your input features so that your model can scale with a high degree of accuracy and precision.
Thus, exploratory data analysis (EDA) and preprocessing matters even with neural nets.
What is model convegence?
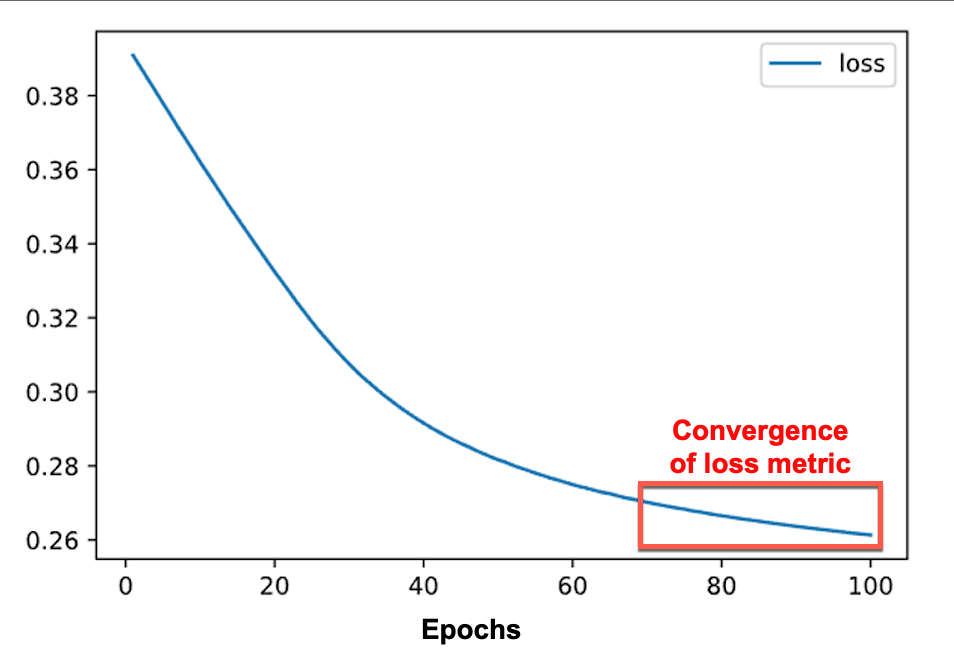
When we say a model has converged, we mean that in a loss function graph, increasing the number of epochs or iterations will not improve the model in terms of reducing errors.
Take the Guesswork Out of Model Optimization
Let’s open up the file(s) in the 04-Ins_AutoOptimization folder to get started.
What is hyperparameter tuning?
Hyperparameter tuning is how we should configure our model so that it performs optimally to the best results against our training and validation data sets.
This is in the hopes of deploying the best ML model/product that we can offer.
Hyperparameter tuning does not exist only in deep learning. In fact, it exists in almost all known ML models, such as:
- XGBoost
- Logistic algorithms
- And so on…
A lot of the hyperparameter tunning process can be automated where the library would brute force a bunch of configurations to find out the best accuracy to loss in your outcome.
How does hyperparameter work in general?
In many cases, it is a brute force method of defining the best optimal configuration parameters for your objective (in our case, usually accuracy).
As shown in the above instructor’s activity, the tuner will iterate across different configurations in terms of:
- Switching between the activation function
- Running the number of neurons from 1 to 10 in the first layer
- Configure from 1 to 6 hidden layers, where each layer can have 1 to 10 neurons.
This means hyperparameter is very time consuming and resource heavy. Typically, we will create a proof-of-concept model, run a few tests, ensure we are doing proper feature engineering, and create a summarized report of our model before attempting to tune the model.
The same concept works for other learning models as well.
Students Do: Giving Your Model Building a Tune-Up
Let’s open up the file(s) in the 05-Stu_TuneUp folder to get started.
Getting Real with Neural Network Datasets
Let’s open up the file(s) in the 06-Ins_GettingReal folder to get started.
Ref: https://static.bc-edx.com/data/dl-1-2/m21/lessons/2/img/NN_Preprocess_Flowchart.pdf
There could be an error on the 4th cell, where the code was:
encode_df.columns = enc.get_feature_names(attrition_cat)
There is a recent update on scikit-learn library, and they have renamed their method to:
encode_df.columns = enc.get_feature_names_out(attrition_cat)
What is the difference between pd.get_dummies() vs OneHotEncoding by sci-kit learn?
- OneHotEncoding is generally preferred because of persistance.
- When you use
pd.get_dummies(), it will only encode the data into categorical variables that are currently present in the dataset. However, if you have additional data sets that contains additional categorical variables, but you did not encode them from the previous runs, you will get a conflict in terms of training data. - OneHotEncoding does not have the flaw because it stores the categorical variabels into memory. Thus, if additional categorical values appear within the dataset in the future, it will create new values appropriately without conflict.
- When you use
pd.get_dummies()is good for preliminary analysis, but OneHotEncoding should be what you deploy on production.
Students Do: Detecting Myopia through Deep Learning
Let’s open up the file(s) in the 07-Stu_DetectingMyopia folder to get started.
